@Yusaku Ogawa さん、こんにちは
この文字コード問題。意外と正しい答えに行き着くのが難しい話のと、知らないでor楽観して運用していると恐るべき事に陥る罠の1つなのでご注意ください。そんな私はマルケト運用初期のころに、悪夢の3万リード文字化け事件という経験をし、そこから気をつけるようになりました。
もしかしたら結論として「UTF-8変換はした上での症状ですよ」ということかもしれませんがその際はご了承ください。
コメントされた安藤さんも、もしや、まだ危険地帯におられるかもしれない。。。という気もしたので、私からもコメントさせて頂きます。
まず、大丈夫という認識はあったのですが、一応心配になったので、試しに「髙」の文字をFirst NameにしたListを作ってImportしましたが、特に問題なく処理されました(List Importは常に慎重)。下記の通りです。
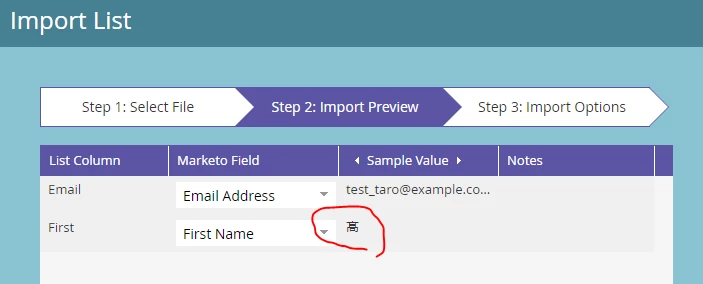
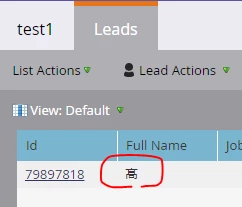
UIは英語ですけど、そこは動作に関係ないです。
さて、これですが、"文字コード"は残念ながら今でも気をつけなければ行けない日本語の悩みの1つです。
そして、私もそうですが、なまじ長くコンピュータを触ってきた方ほど、今時の文字コードの扱いでハマる(=誤解がある)かもしれません。
「半角英数字は1バイト、全角は2バイト」と、思っている方!(=私も長らくそうでしたけど)。危険です。ご注意ください 。
。
今の常識は「全角は3バイト(だいたい)」です。そして、全角3バイトなおかげで、昔は機種依存文字だったものの多くが、依存文字のレッテルを剥がされています。
細かい話は長くなるので割愛しつつの説明ですが、Importに使うファイルをExcelで作業されたあとに文字コードをUTF-8に変更する処理を別途されていますか?マルケト含めて、今時のモダンなシステムは文字コードにUTF-8を使っています。UTF-8の場合、漢字の「髙」などもしっかりコードが割り振られているので文字が化けることは基本ありません。
こちら、その該当部分のMarketo Docsです。下記は英語の注意書き。
Import a List of People - Marketo Docs - Product Docs

同じ部分の日本語版の注意書きです。

後半に一行たされてますね。
残念ながらExcelはファイル保存時に直接文字コードをUTF-8にしてCSVを保存することができません。そのため、CSVに保存した後で、そのファイルを別のツールでShift-JIS→UTF-8に変換してあげる必要があります。
一番簡単なのは、Windowsなら「メモ帳」で可能です。メモ帳でCSVファイルを開いて、保存時に「UTF-8」というオプションが選べるのでそれで保存すればUTF-8形式のCSVファイルが完成します。
変換が面倒。。。ということであれば、Excelで"unicode形式"で保存したファイルを使う手段もあります(この場合、全ての文字が1文字4バイト)。それで読み込んでもImportできます。ただし。。。。私は気味が悪いので、手間ですがUTF-8に自前で変換したファイルをImportに使うようにしています。なぜなら、Marketoからアウトプットする(Webやメールなど)ときに使われる文字コードがUTF-8なので素直にそのままデータが流れてくれる(はずだ)からです。色々なトラウマがあるので慎重です 。
。
最後に、メールの送り先、Webの閲覧時などで、無事に入れた文字が正しく表示されるか?という心配についてですが、B2Bならちょっと昔のPCやスマートフォン程度なら問題ないので、そこまで心配しなくても良いかなと割り切ってます。B2Cでという場合、私はキャリアメールなどの今時事情に詳しくないので、そのあたりは分かりません(B2Bの担当なもので。。。)。
以上、ご参考までに。
最後に「Excelでunicode形式で保存したファイルそのまま多数Importしてるけど問題ないよ!」という方おられましたら教えてください。
-Yamada